Introduction
Introduction
The use of sophisticated machine-learning (ML) algorithms and artificial intelligence models in risk modelling and fraud detection has seen a marked spike in recent years. The real-world performance of these ML models relies heavily on the quality and quantity of data available for training and calibration of such models. Economic and financial datasets are commonly plagued by ‘data imbalance’, which can result in underperforming models. A data or class imbalance occurs when the target variable in a training dataset has an uneven distribution (i.e., the number of data points in one class or category is significantly lower than that in the other). Models trained by using imbalanced datasets can show high overall accuracy; however, when looked at closely, they demonstrate poor predictive power on the minority class. High model accuracy in such cases can, therefore, be misleading and result in significant financial losses. To reduce model risk, it becomes necessary to treat datasets using a suitable method prior to the model building exercise.
In this white paper, we discuss in detail the methods that can alleviate issues arising out of data imbalance, leading to robust and well-performing models.
What is data imbalance
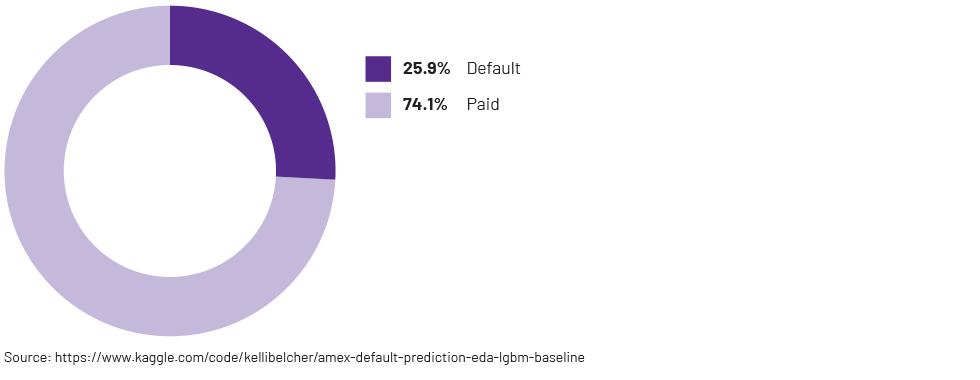
Under normal conditions, defaults occur infrequently compared to non-defaults. Similarly, instances of fraud are rare in comparison to genuine transactions. This uneven distribution, where one class (non-defaults, genuine transactions, etc.) significantly outnumbers the other class (defaults, fraudulent transactions, etc.), naturally leads to the creation of imbalanced datasets. Here, the class consisting of fewer datapoints is referred to as the minority class, while the class with a larger number of datapoints is termed the majority class. Such imbalances can compromise recall scores (or true positive rate) and impact overall model performance.
Figure 1: Target variable distribution in a credit card default dataset
Impact of imbalanced datasets
Imbalanced datasets can prompt ML models to misclassify the minority class more frequently. This misclassification is a concern, particularly in scenarios where the correct identification of the minority class is crucial, such as in fraud detection or credit risk modelling. Models trained using imbalanced datasets have a greater tendency to favour the majority class, leading to sub-optimal decision-making and potential financial losses.
Figure 2: Comparison of decision boundaries (generated using logistic regression model) between an imbalanced dataset and a balanced dataset.
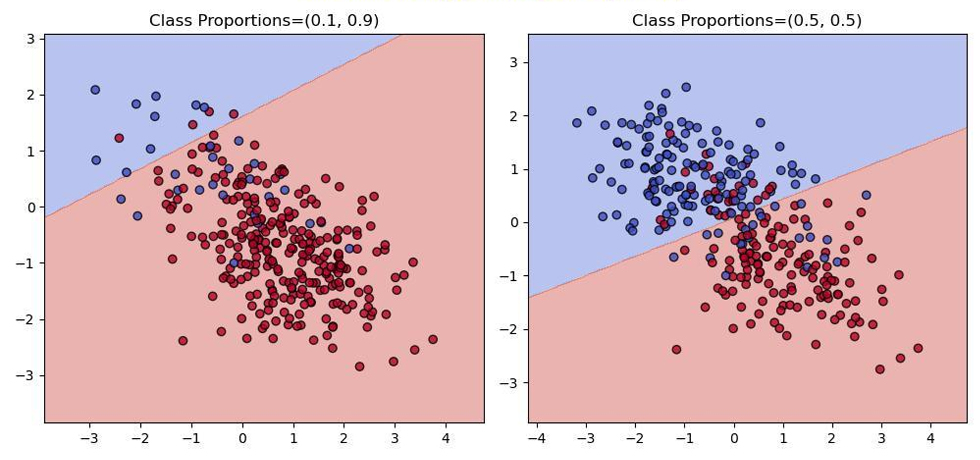
Figure 3: Comparison of decision boundaries (generated using logistic regression model) between an imbalanced dataset and a balanced dataset.
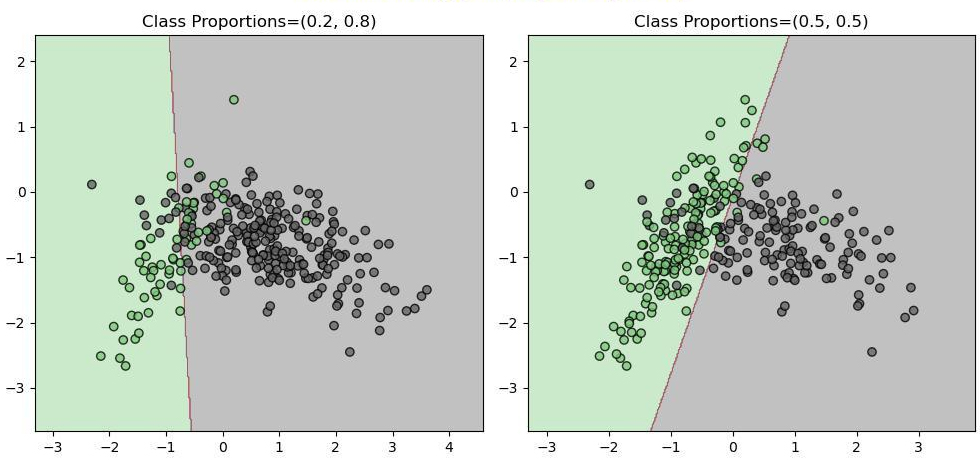
How to handle data imbalance
Several techniques can be used to address data imbalance:
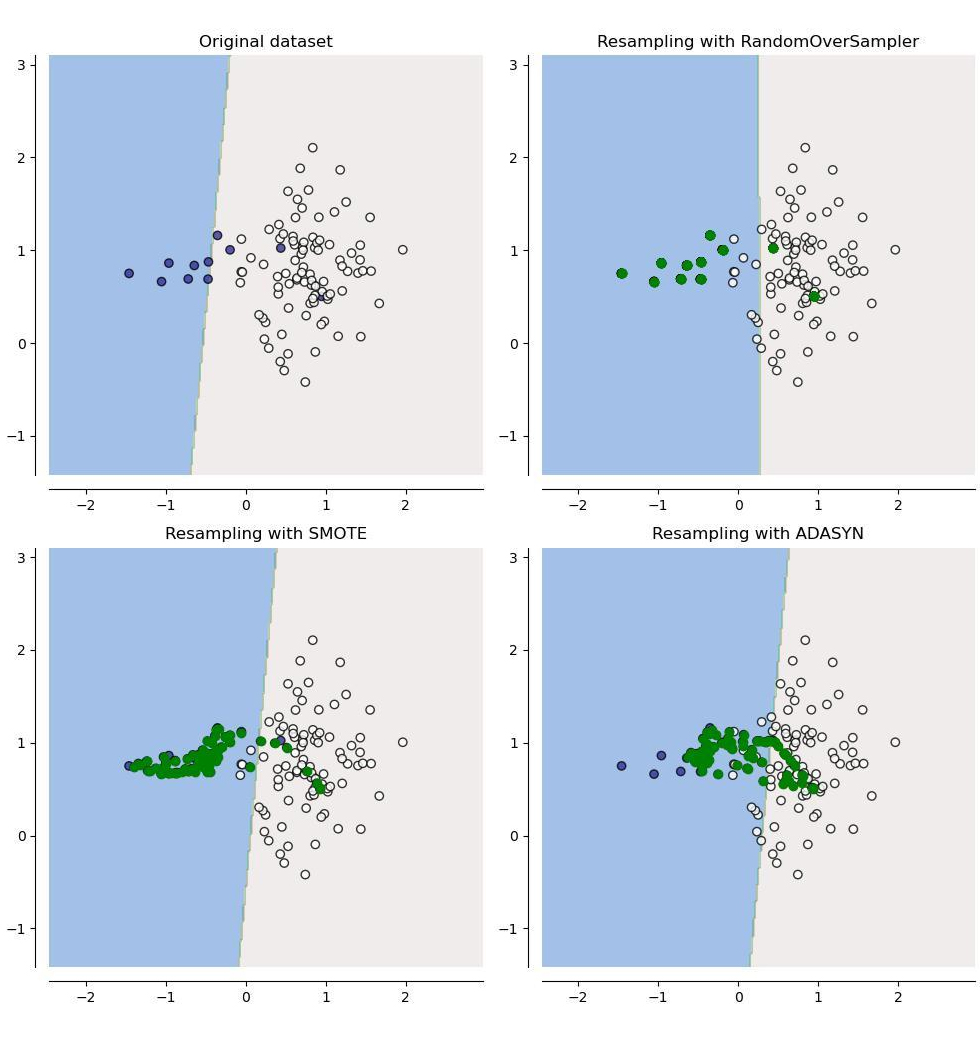
Resampling: It is a simple process that involves either the creation of duplicate datapoints pertaining to the minority class or the removal of a fraction of datapoints corresponding to the majority class to create a balanced dataset.
SMOTE (synthetic minority oversampling technique): This method creates synthetic samples in the neighbourhood of the minority class samples by using an interpolation technique.
ADASYN (adaptive synthetic sampling approach): Similar to SMOTE, ADASYN generates synthetic samples but focuses on regions where classification algorithms find it harder to learn the distinction between minority class and majority class samples.
- GANs (generative adversarial networks): GANs are neural network models capable of creating realistic synthetic samples by learning the properties of the underlying data distribution.
Figure 4: Depiction of synthetic samples (shown in green) generated using different resampling techniques.
Case study
A case study, presented in the white paper, demonstrates the improvements in model performance when a model training dataset is treated using the oversampling, ADASYN and SMOTE techniques. A logistic regression model is trained on the treated dataset (balanced dataset) as well as the imbalanced dataset. The differences in key model performance metrics when data handling methods are used and when they are not used are compared and discussed.

Conclusion
Addressing data imbalance is crucial for building robust financial models. Techniques such as resampling, SMOTE, ADASYN and GANs can help mitigate the effects of data imbalance, leading to more accurate and reliable models.
How Acuity Knowledge Partners can help
Acuity Knowledge Partners offers expert model-development-and-validation services to ensure models are resilient and compliant with regulatory standards.
About the Author

Raunaq Freeman is a member of Investment Operations and Risk Services line of business at Acuity Knowledge Partners. He has a strong background in statistical modeling, machine learning and quantitative finance. He has validated a variety of models as part of Model Risk Management engagements with US banks and Asset managers. The models he has validated include Credit Risk models, Derivative pricing models, PPNR, Scenario Design and BSA\AML models.

Thank you for sharing your details
Share this on


