
Published on May 3, 2021 by Manoj Fernando
Using stream-processing technologies to build a highly scalable AML pattern-detection and alerting platform
If your AML detection platform can flag a potentially fraudulent transaction only way after the event has occurred, it is probably not serving its purpose very well, is it? At the same time, if your AML validation process causes significant delays to the main transactions workflow, that’s not going to please your customer either.
So how do we tackle the issue of scaling an AML detection platform to support millions and millions of events, without compromising the number of validations we need to perform against each transaction? How do we make sure the user experience is not compromised and other transactions are not kept waiting a significantly long time while your AML validations are taking place in the background?
A solution based on real-time stream processing may hold the answer to this problem. Depending on the context of its application, stream processing is also known as real-time analytics, event processing, streaming analytics, and by quite a few other names. Irrespective of how you want to call it, the fundamental problem these stream-processing frameworks have been designed to address remains the same. That is to analyse data as soon as an event takes place in a context where accurate and meaningful signals can be generated. There are so many use cases where stream-processing techniques can be applied – not just within the financial domain, but also across many other domains that depend heavily on timely analysis of data as it occurs.
So how do we design a platform that can be scaled for AML pattern detection in real time?
Let’s take an example of how we can analyse and report any unusual behaviour for a new account, comparing it with the defined path for detecting anticipatory behaviour. Here, our business logic needs to analyse each inbound transaction for the following four points.
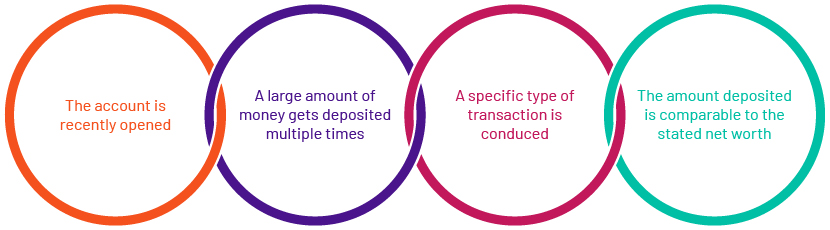
Let’s derive parameters for the above mentioned points to identify the deviation anticipatory behaviour comparison and assign some standard values to begin with:
1. For an account recently opened = Account age <= 180 days
2. Type of transaction defined, balance deposit = IN-DEP
3. Amount of funds getting deposited over a week = Deposit value >=USD15K
4. Number of times the age of the account is within the new account age, and Occurrences >1
5. Ratio of the amount deposited and stated net worth is almost greater than 1 = Ratio of funds deposited and stated net worth >=1.25
At a glance, you should be able to see that there are a number of activities that need to be performed before others. If a certain validation depends on inputs from a preceding validation, then it is what it is. There is nothing we can do to break that sequence. However, wherever we can run activities in parallel, we absolutely must make every attempt to optimise processing time. For a platform that should scale for millions of transactions, such design considerations are an absolute must.
I also wish to highlight something about the technical architecture. If you are compelled to pull transactions off a database during the pattern-detection chain, that is probably not a good design given the number of I/O calls involved per workflow. However, if your transactional data lands on a stream-processing platform such as Apache Kafka, and if you can pre-load the dependent data onto in-memory data structure, you have laid the foundation for building a robust platform.
I have used Apache Kafka for this proof of concept, but if you are more biased towards using a cloud platform instead, of course you have similar options to choose from. I will keep that discussion for another day.
Let’s take a look at high-level architecture and how it all connects.
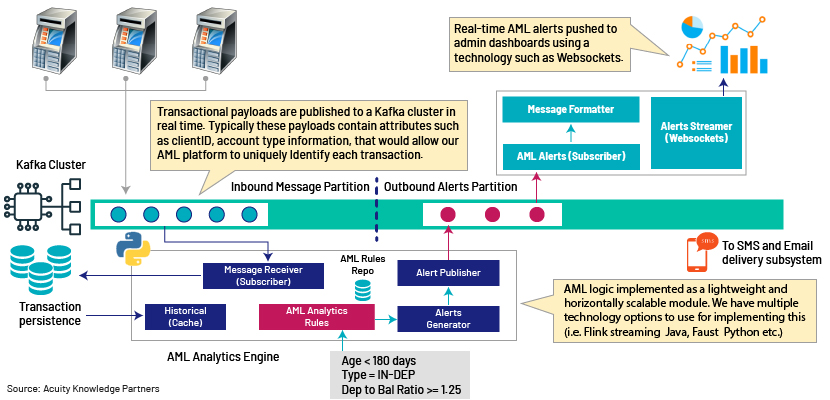
The very first point of integration is the Kafka cluster, where transactions are published as and when they occur to one or more topics. Each transaction is then picked by one or more instances of a stream-analytics engine – the core of the AML detection platform. Depending on your AML workflow, you have the flexibility to define Kafka topics to achieve maximum concurrency and thereby reduce the overall processing time across the detection rule chain.
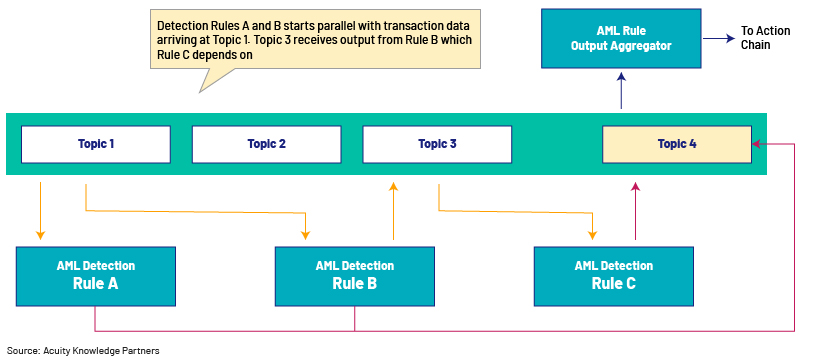
Source: Acuity Knowledge Partners
The transactional data can be sprayed into an array of Kafka topics, based on the need. If you look at the above example, transactions data arriving at Topic 1 is immediately consumed by Detection Rules A and B that run in parallel. Rule C, which depends on the output from Rule B, will listen to Topic 3 for instructions and data. Topic 4 would be the final aggregator of outputs from all detection rules that will trigger a chain of downstream actions based on the overall execution status. This sort of arrangement would also allow you to take actions on the first occurrence of a detection rule triggering non-compliance, so that the workflow does not need to wait unnecessarily for all other detection rules to be completed.
There are a few options to choose from to implement this part of the solution, such as Apache Flink/Spark Streaming, Python Faust and WSO2 CEP. Our AML detection logic should ideally sit on top of these frameworks as lightweight components wiring to/from the Kafka cluster.
A key point to outline about this architecture is the non-blocking design patterns used throughout the data pipeline. To scale to support millions of transactions within shorter timeframes, it is absolutely essential to not cause delays to other transactions entering the platform.
Summary
The purpose of this article is to provide an overview of how Acuity Knowledge Partners can build a highly scalable AML detection platform that can detect patterns and trigger signals in real time. We bring the agility to work with your in-house technology teams to build a platform such as this, or build and operate as a vendor-managed solution, if that is preferred.
References:
1. Apache Kafka: https://kafka.apache.org/documentation/
2. Python stream processing: https://faust.readthedocs.io/en/latest/
3. Flink stream processing: https://flink.apache.org/
Tags:
What's your view?

Thank you for sharing your Comments
Share this on


About the Author

Manoj is responsible for IT Strategy and Enterprise Solution Architecture for BEAT Custom Technology Solutions under the Specialised Solutions practice at Acuity Knowledge Partners. He works with multiple clients, providing support to the solution architecture and technology strategy. He has over 21 years of experience in developing enterprise solution architecture and formulating technology strategies.
 Blog
Blog
Decoding SWIFT’s MT-to-MX migration – ch....
The global financial messaging space has taken centre stage since the migration to ISO 200....Read More
 Blog
Blog
Navigating global compliance challenges with Acu....
In the fast-paced world of finance, with constantly evolving regulations and high stakes, ....Read More
 Blog
Blog
Maximising Efficiency in Customer Onboarding: Di....
Introduction Customer onboarding or account opening refers to the process by which indivi....Read More
 Blog
Blog
Is football on the buy side?
With the UEFA Champions League (UCL) final still playing in our minds, we decided to colle....Read More
 Blog
Blog
ESG investing – beginner’s guide to respo
ESG investing in private markets integrates environmental, social and governance (ESG) att....Read More
 Blog
Blog
Data prerequisites of index rebalancing – i
Introduction Index rebalancing is a mechanism to keep an index accurate. It is the proces....Read More
Like the way we think?
Next time we post something new, we'll send it to your inbox